![]()
Enterprise JavaBeans - Part 1
Writing distributed enterprise applications has always been a significant challenge, but this once Herculean task has been somewhat ameliorated with the advancement of component-based programming in general. For example, by increasing program modularity, you can now compose a behemoth application from multiple functionally independent modules. This not only enables you to assemble complex systems using an assembly-line approach, but also greatly increases the reusability of the modules themselves.
Although using components enhances the modularity and natural distribution of applications in general, they still present some interesting challenges. For example, in days of old, when a monolithic program failed, it was simply restarted as a unit. But, today, with a modular system, when a failure of any one component occurs, the challenge is to ensure faults are isolated to limit their propagation and that it does not corrupt others. This is more complicated than it sounds with distributed applications, however, as the components can reside anywhere on the network. In addition, because enterprises are essentially heterogeneous environments, the presence of multiple operating systems and platforms that host the different components adds a new level of complexity.
Clearly, a technology like Java, with its promise of the "write once run anywhere," can significantly mitigate many of the problems associated with enterprise distributed systems development. This chapter is devoted to understanding the implications and architecture of an enabling server-side component technology—Enterprise JavaBeans (EJBs)—and presents examples of how to use this technology to implement real-life, distributed enterprise solutions.
Backgrounder—The Relevant Technologies
Before we explore EJBs, you should first understand what enterprise applications are all about. Although covering the entire spectrum of details is impossible, we’ll examine some of the more important concepts before going in for an enterprise solution.
What Are Transactions?
A transaction is the most important concept you should be aware of when dealing with enterprise applications. To a user, a transaction is a single change event that either happens or doesn't happen. To system implementers, a transaction is a programming style that enables them to code modules that can participate in distributed computations. To illustrate this concept, assume you want to transfer money from a savings account into a checking account. In this scenario, it is critical that both the accounts are changed from a successful transaction and neither is affected from an unsuccessful one. You cannot afford to have your money vaporize if crediting your checking account fails for any reason after the debit on your savings account! Although this may sound like a fairly straightforward request, making this work in a distributed system without deploying some form of transaction control is hard—computers can fail and messages can easily get lost.
Transactions provide a way to bundle a set of operations into an atomic execution unit.
This atomic, all or nothing property is not new: it appears throughout life. For example, a minister conducting a marriage ceremony first asks the bride and groom, "Do you take this person to be your spouse?" Only if they both respond "I do" does the minister pronounce them married and commit the transaction. In short, within any transaction, several independent entities must agree before the deal is done. If any party disagrees, the deal is off and the independent entities are reverted back to their original state. In transactions, this is known as a rollover operation.
Transactions are essential for distributed applications. Further, transactions provide modular execution, which complements a component technology’s modular programming.
The ACID Properties
All transactions subscribe to the following "ACID" properties:
Atomicity: A transaction either commits or rollbacks. If a transaction commits, all its effects remain. If it rollbacks, then all its effects are undone. For example, in renaming an object, both the new name is created and the old name is deleted (commit), or nothing changes (rollback).
Consistency: A transaction always leads to a correct transformation of the system state by preserving the state invariance. For example, within a transaction adding an element to a doubly linked list, all four forward and backward pointers are updated.
Isolation: Concurrent transactions are isolated from the updates of other incomplete transactions. This property is also often called serializability. For example, a second transaction traversing a doubly linked list already undergoing modification by a first transaction, will see only completed changes and be isolated from any noncommitted changes of the first transaction.
Durability: If a transaction commits, its effects will be permanent after the transaction commits. In fact, the effects remain even in the face of system failures.
The application must decide what consistency is and bracket its computation to delimit these consistent transformations. The job of the transactional resource managers is to provide consistent, isolated, and durable transformations of the objects they manage. If the transactions are distributed among multiple computers, the two-phase commit protocol is used to make these transactions atomic and durable.
The Java Transaction Service
The Java Transaction Service (JTS) plays the role of a transaction coordinator for all the constituent components of the EJB architecture. In JTS terminology, the director is called the transaction manager. The participants in the transaction that implement transaction-protected resources, such as relational databases, are called resource managers. When an application begins a transaction, it creates a transaction object that represents the transaction. The application then invokes the resource managers to perform the work of the transaction. As the transaction progresses, the transaction manager keeps track of each of the resource managers enlisted in the transaction.
The application's first call to each resource manager identifies the current transaction. For example, if the application is using a relational database, it calls the JDBC interface, which associates the transaction object with the JDBC connection. Thereafter, all calls made over that connection are performed on behalf of the database transaction until it ends.
Typically, the application completes the transaction by invoking a xa_commit() method and the transaction is said to commit. If the application is unable to complete for any reason, it performs a rollover by calling the xa_rollback() method, which undoes the transaction's actions. If the application fails, the JTS aborts the transaction. When the application successfully completes the transaction's work, it calls the JTS to commit the transaction. The JTS then goes through a two-phase commit protocol to get all the enlisted resource managers to commit.
Two-phase Commits
The two-phase commit protocol ensures all the resource managers either commit a transaction or abort it. In the first phase, the JTS asks each resource manager if it is prepared to commit. If all the participants affirm, then, in the second phase, the JTS broadcasts a commit message to all of them. If any part of the transaction fails—for instance, if a resource manager fails to respond to the prepare request or if a resource manager responds negatively—then the JTS notifies all the resource managers the transaction is aborted. This is the essence of the two-phase commit protocol.
What Is a Naming Service?
A naming system provides a natural, understandable way of identifying and associating names with data. For example, the DOS file system uses a naming system for associating data with folder and file names, while a relational database uses a naming system for associating data with column and table names. Naming systems enable humans to interact with complex computer addressing systems by associating data and objects with simple, understandable names.
A naming service is a dedicated piece of software that manages a naming system or namespace. Naming services often run independently of the computer systems that use them. In other words, they provide the service of associating names with data or objects—a naming system—but are independent and can serve any system that understands their protocol and can connect to them.
Directory and naming services usually employ two layers: a client layer and a server layer. The server is responsible for maintaining and resolving the actual name—object bindings, controlling access, and managing operations performed on the structure of the directory service. The client acts as an interface that applications use to communicate with the directory service.
The Java Naming and Directory Interface
The Java Naming and Directory Interface (JNDI) shown in Figure 1 is a client API that provides naming and directory functionality. JNDI is specified in Java and is designed to provide an abstraction that represents those elements most common to naming and directory service clients. JNDI is not intended as an alternative to established naming and directory services. Instead, it is designed to provide a common interface for accessing existing services like DNS, NDS, LDAP, CORBA, or RMI.
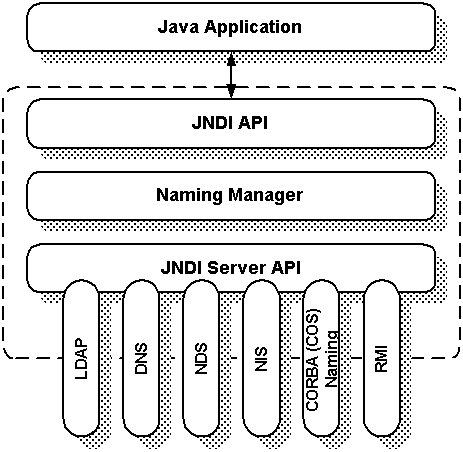
Figure 1: The Java Naming and Directory Interface
JNDI provides an interface that hides the implementation details of different naming and directory services behind the JNDI API. This allows multiple directory services to coexist and even cooperate within the same JNDI client. Using JNDI, a user can navigate across several directory and naming services while working with seemingly only one logical federated naming service.
JavaBeans—The Generic Component Model
A component model defines an environment that supports reusable application components. Java defines a generic component model called JavaBeans for linking together pieces of code like Lego building blocks, to form an applet or application. Today, hundreds of JavaBean components are readily available, with a number of tools supporting their use.
Any object that conforms to certain basic rules as defined in the JavaBeans API can be a JavaBean. In addition to having a default constructor and being serializable, a JavaBean exports properties, events, and methods. Properties indicate the internal state of a Bean and can be manipulated using a pair of get and set methods (getter/setter methods). A Bean is also capable of generating events and follows the Java 1.1 Delegation Event Model for generating them. A bean defines an event by providing methods for adding and removing event listener objects from a list of interested listeners for that event. Bean methods are any public methods the bean exposes (except the getter/setter methods) to change property values or the methods to register and remove event listeners.
In addition to this, JavaBeans also define indexed properties, bound properties, and constrained properties. An indexed property is a property that has an array value and methods to change the value of either an individual array element or the entire array. A bound property is one that sends out a notification event when its value changes. A constrained property is one that sends out a notification when its value changes and allows the change to be vetoed by its listeners.
A bean can also provide a BeanInfo class that provides additional information about the bean in the form of FeatureDescriptor objects, each of which describe a single feature of the bean. If a bean has complicated property types, it may need to define a PropertyEditor class that enables the user to set values for that property. A bean can also define a Customizer class, which creates a customized GUI that enables the user to configure the bean in some useful way.
Note |
| The acronym
EJB is used interchangeably to denote a component
and an architecture. Some confusion exists because, in
the specification, EJB is used both as an acronym for an
Enterprise JavaBean (EJB)—the component—and for
Enterprise JavaBeans—the architecture. A packaged EJB component is identified by multiple individual elements :
An EJB component is specified as the combination of the three elements and its deployment descriptors. You can change any one of those elements and create a new and unique EJB (for example, in most servers, EJBs can differ by remote interface only or by Enterprise Bean class implementation only, or by deployment data only, and so forth). In that light, a descriptor uniquely specifies an EJB component. |
Enterprise JavaBeans—Components at the Server
Enterprise JavaBeans (EJB) takes a high-level approach for building distributed systems. It frees the application developer to concentrate on programming only the business logic, while removing the need to write all the "plumbing" code required in any enterprise application development scenario. For example, the enterprise developer no longer needs to write code that handles transactional behavior, security, connection pooling, or threading because the architecture delegates this task to the server vendor.
The current version of EJB bears little relation to JavaBeans. The name "Enterprise JavaBeans," however, implies a relationship that doesn't really hold. Typically, JavaBeans are used in a manner similar to Microsoft’s ActiveX components (to provide user-friendly controls for building user interfaces), whereas EJBs are used to implement transactional middleware and are decidedly nonvisual. In addition, EJB does not include things like BeanInfo classes, property editors, or customizers.
In essence, EJB is a server component model for Java and is a specification for creating server-side, scalable, transactional, multiuser, and secure enterprise-level applications. Most important, EJBs can be deployed on top of existing transaction processing systems including traditional transaction processing monitors, Web servers, database servers, application servers, and so forth.
Why Use EJB?
In applications like Microsoft’s Visual Basic, a property window exists, which can be used as a simple, code-free means of programming various objects that are part of an application. Similarly, Sybase’s PowerBuilder, has a data window, which allows a code-free means of programming data access to database applications. EJB brings a similar concept to building enterprise applications. Users can now focus on developing business logic with ease, while being shielded from the nitty-gritty aspects of enterprise application development through the use of EJB components.
In an n-tier architecture, it does not matter where the business logic is, though in a typical 3-tier architecture, the business logic is normally in the middle-tier by convention. With EJB, however, you can now move your business logic wherever you want, while adding additional tiers if necessary. The EJBs containing the business logic are platform-independent and can be moved to a different, more scalable platform should the need arise. If you are hosting a mission-critical application and need to move your EJBs from one platform to the other, you can do it without any change in the business-logic code. A major highlight of the EJB specification is the support for ready-made components. This enables you to "plug and work" with off-the-shelf EJBs without having to develop or test them or to have any knowledge of their inner workings.
The primary advantages of going in for an EJB solution are
Differences Between JavaBeans and Enterprise JavaBeans
Table 1 summarizes some of the major differences between a JavaBean and an Enterprise JavaBean.
| JavaBeans | Enterprise JavaBeans |
| JavaBeans may be visible or nonvisible at runtime. For example, the visual GUI component may be a button, list box, graphic, or a chart. | An EJB is a nonvisual, remote object. |
| JavaBeans are intended to be local to a single process and are primarily intended to run on the client side. Although one can develop server-side JavaBeans, it is far easier to develop them using the EJB specification instead. | EJBs are remotely executable components or business objects that can be deployed only on the server. |
| JavaBeans is a component technology to create generic Java components that can be composed together into applets and applications. | Even though EJB is a component technology, it neither builds upon nor extends the original JavaBean specification. |
| JavaBeans have an external interface called the Properties interface, which allows a builder tool to interpret the functionality of the bean. | EJBs have a deployment descriptor that describes its functionality to an external builder tool or IDE. |
| JavaBeans may have BeanInfo classes, property editors, or customizers. | EJBs have no concept of BeanInfo classes, property editors ,or customizers and provide no additional information other than that described in the deployment descriptor. |
| JavaBeans are not typed. | EJBs are of two types—session beans and entity beans. |
| No explicit support exists for transactions in JavaBeans. | EJBs may be transactional and the EJB Servers provide transactional support. |
| Component bridges are available for JavaBeans. For example, a JavaBean can also be deployed as an ActiveX control. | An EJB cannot be deployed as an ActiveX control because ActiveX controls are intended to run at the desktop and EJBs are server side components. However, CORBA-IIOP compatibility via the EJB-to-CORBA mapping is defined by the OMG. |
Table 1: Differences between JavaBeans and Enterprise JavaBeans
You can always refer to my Homepage at http://www.execpc.com/~gopalan for more EJB source code. Another good resource is the EJB-INTEREST@JAVA.SUN.COM mailing list from Sun and the EJBHome mailing list ejbhome-discuss@iona.com from Iona.
| About the Author... |
| Gopalan Suresh Raj is a Software Architect, Developer and an active Author. He is contributing author to a couple of books "Enterprise Java Computing-Applications and Architecture" and "The Awesome Power of JavaBeans". His expertise spans enterprise component architectures and distributed object computing. Visit him at his Web Cornucopia© site (http://www.execpc.com/~gopalan) or mail him at gopalan@execpc.com. |
|
This site was developed and is maintained by Gopalan Suresh Raj This page has been visited |
|
Last Updated : Dec 19, '98 |
||
Copyright (c) 1997-2000, Gopalan Suresh Raj - All rights reserved. Terms of use. |
All products and companies mentioned at this site are trademarks of their respective owners. |
