CORBA AS INFRASTRUCTURE FOR DATABASE INTEROPERABILITY
JIAN HU, CHRIS MUNGALL, DAVID NICHOLSON, ALAN L ARCHIBALD
Roslin Institute Edinburgh
Roslin, Midlothian EH25 9PS
UK
Abstract
Database interoperability involves data sharing among heterogeneous databases. We present a brief review of this issue based on the ‘classical’ 5-level federated database systems proposed by Sheth and Larson [1], followed by a description and analysis of multidatabase interoperation in the Internet environment. We then examine Common Object Request Broker Architecture (CORBA) and CORBA-based systems development, and CORBA as an infrastructure for database interoperability. A system architecture is proposed in which each local database exposes itself through a wrapper specified by Interface Definition Language (IDL). A ‘federated IDL’ or an application can be created on top of local IDLs, in order to perform database interoperation. The role of a data dictionary is emphasized in this framework and we further specify the data dictionary using IDL. A system prototype for a biological application based on the proposed architecture is briefly described. We conclude the paper with a summary and proposals for future work in this area.
Keywords:
CORBA, IDL, database, interoperability, data dictionary.
1. INTRODUCTION
1.1. Database interoperability: a classical view
Despite considerable research and development, database interoperability still presents significant challenges, the major obstacle being heterogeneity. Heterogeneities can be categorized and analyzed in different frameworks. Sheth and Larson divide heterogeneities into those due to the differences in database management systems (DBMSs) (referred to as system heterogeneities) and those due to the differences in the semantics of data (referred to as semantic heterogeneities) [1]. Another framework given in [2] is based on the observation that data sharing may be at a number of levels of abstraction and granularity, ranging from data model (relational or object oriented), conceptual schema, object comparability, data form/format to DBMSs and tools.
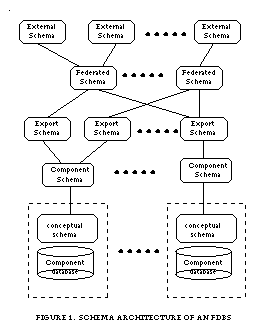
Sheth and Larson presented an excellent survey in [1] which includes a complete review of architecture, components and development strategies for database interoperability. A proposed architecture adapted from [1] is shown in Figure 1. A local schema is the conceptual schema of a participating database. A component schema is derived by translating local schemas into a data model called the canonical or common data model (CDM). The CDM is usually object oriented due to its semantic richness [3]. An export schema represents a subset of a component schema that is available to the federated system. A federated schema is constructed upon multiple export schemas. An external schema defines a schema for a user/application or a group of users/applications.
Generally, interoperating databases fall into two categories: tightly coupled and loose coupled systems according to the different methods of construction of the federated schema. A tightly coupled system involves defining a common global schema which integrates all or a portion of the local schema of each participating database. A federal user can query against the federated schema or external schema with the illusion that the user is accessing a single system. A loosely coupled system asks the user or programmer to construct the federated schema. The user first looks at the relevant export schemas, then defines a federated schema by importing the export schema objects using a set of operators or a multidatabase language. An example of the multidatabase language is MSQL presented by Litwin which is an extension of SQL [4].
1.2. Database interoperability in the Internet: current practices
1.2.1. Web/HTTP
The World Wide Web (WWW or Web) has been widely used for information delivery. The underlying protocol used in the Web is Hyper-Text Transfer Protocol (HTTP). A web server accepts HTTP requests from clients and returns the results usually in the Hyper-Text Markup Language (HTML) format. Any user can use a Web browser like Netscape or Internet Explorer as a Web client to access the information from a web server as long as the user knows the server’s Uniform Resource Locator (URL). The Web technology is pervasive and has greatly enhanced use of the Internet.
Database access is a key issue for information delivery in the Internet environment. Database access through a Web server is performed typically via the Common Gateway Interface (CGI) (or another interface) facility provided by the Web server. When a request arrives from a client, the Web server invokes a dedicated CGI program to access the data in the database and to produce the data in HTML form. Although a data provider can link his/her information to that in other data sources by embedding the URLs of the other data objects in the HTML, it does not provide database interoperability since no processing upon the data obtained from different databases is performed.
In order to use Web/HTTP as an infrastructure for database interoperation, it is essential that each database can be accessed via HTTP and delivers its data in an agreed format. Once again, a CGI program may be employed for this purpose. A client program issues HTTP requests to those Web servers where relevant databases reside. The data are returned in an agreed format and then some processing upon these pieces of data may be performed by the client. This client may be a stand-alone application program, or a CGI program in a Web server which is invoked by a Web browser in turn, or a Java applet. A Java applet is downloaded from a Web server and is interpreted at the browser. The main consideration for this scenario is Java’s security restriction, i.e. a Java applet is not allowed to make any connection to a host other than one it is from. This restriction can be resolved by using the ‘object signing’ technique [5].
The Web-based multidatabase interoperation described above may be thought of as a kind of ‘loosest coupled’ system where each system only agrees to present its data in common syntax. An obvious disadvantage of using Web/HTTP for interoperability is that Web/HTTP was designed for text transfer by its nature and this does not support structured data. The other drawbacks of the HTTP/CGI approach are that it is slow, cumbersome, and stateless.
1.2.2. JDBC
Java Database Connectivity (JDBC) is an industry standard proposed by Sun Microsystem. It defines a Java application programming interface (API) for executing SQL statements. It consists of a set of classes and interfaces written in the Java programming language (JDBC documentation is available at http://java.sun.com/products/jdbc).
The JDBC is often used in a client/server configuration, where a Java applet or application runs on a client machine and talks directly to a database residing on a server machine. This approach requires a JDBC driver that can communicate with the particular database management system being accessed. A user’s SQL statements are delivered to the database, and the results of those statements are returned.
JDBC can also be viewed as a facility for multidatabase interoperability. A JDBC application can connect to multiple databases as long as there is an appropriate JDBC driver for each database involved. The user needs to know the schemas and semantics of participating databases and resolve all the heterogeneities during processing. From this point of view, JDBC can be used as a ‘basic’ multidatabase ‘language’ which can help to create a sort of loosely coupled system.
2. CORBA FOR DATABASE INTEROPERABILITY
2.1. CORBA
At the same time as the Web swept across the world of information delivery, the object broker technology has been favoured by developers for integrating distributed and heterogeneous applications. The Object Management Group (OMG), a consortium of over 800 member organizations founded in 1989 (http://www.omg.org), released a specification of the Common Object Request Broker Architecture (CORBA) [6]. The CORBA specification describes a software bus, called an Object Request Broker (ORB), that provides an infrastructure on which a client can invoke the methods of server objects with knowledge only of what types of operations an object can provide, i.e. the object’s interface.
Object interfaces are defined using the OMG Interface Definition Language (IDL). IDL is a declarative language (not for programming) which forces interfaces to be defined separately from object implementation [7]. IDL is designed to specify the operations and types that an object supports. Within an interface definition, one may define a) types (basic or constructed), b) operations (i.e. methods), and c) attributes which represent the object state. OMG IDL also supports inheritance, an important feature which allows a new interface to be derived from one or more existing interfaces.
IDL is semantically rich and capable of representing an object oriented (OO) data model. Mapping from an OO model to an IDL specification may be straightforward: an object class in the model can be represented as an interface in the IDL; the structure of an object class as type definitions and attributes for the corresponding IDL interface. The relationships between classes can be represented as appropriate methods or attributes in the relevant interfaces. The inheritance relationships among classes can be directly represented using IDL inheritance.
To develop a CORBA-based application, an IDL file is created first. The IDL compiler compiles the file to generate the client side stub and the server side skeleton code. A stub is a mechanism that creates and issues requests on behalf of a client, while a skeleton delivers requests to the CORBA object implementation. The final task for developing a CORBA-based system is then writing the object server code and client application code.
Currently, CORBA has been integrated with the Web and Java to form a new framework for information delivery called the Object Web [8]. The Object Web provides a three-tier architecture to facilitate full-blown client/server application development. The first tier is the client, which can be a traditional Web browser or a new Web-centric desktop. The second tier (or middle tier) runs on any server that can service both HTTP and CORBA clients. The third tier is anything a CORBA service can access, e.g. databases.
Using a distributed processing framework for interoperable databases has been addressed by a few researchers. A comprehensive discussion on this topic can be found in [9], in which augmenting the facilities of a distributed system for inter-database operations and negotiations is proposed. The main approach to performing interdatabase operation under a distributed infrastructure is to wrap a component database with an object ‘shell’ which is described by an IDL specification. Negotiation involves communications among different sites when the system has no knowledge of how to handle parts of a request.
While the previous work [9, 10, 11] put the emphasis on augmenting the distributed system architecture itself, our concern is more pragmatic and concerns how to develop a multidatabase application based on the current architecture and facilities, e.g. on the Object Web described above.
2.2. Development of CORBA-based multidatabase applications
Compared to the ‘classical’ federated database architecture presented in [1], we would see some structural similarities between IDL interfaces of participating databases in a CORBA environment and export schemas in a federated system. It should be noted that there may be more than one IDL specifications upon a database, each catering for a particular requirement. We will discuss development issues for such a system in this subsection.
2.2.1 Local IDL design and object implementation
The local IDL is analogous to the export component level in Figure 1. IDL design for a database should aim at capturing semantics of the underlying database. A general procedure would be first to model the relevant objects and their relationships at a conceptual level. This model reflects how users perceive the system, e.g. how the data is classified, what operations are required upon the data. The model can be constructed using methodologies, such as Object Modeling Technique (OMT) [12]. Based on the conceptual model, an IDL file can be designed.
The main object implementation issue is to perform mappings between IDL objects and the data stored in the database. There are two strategies for this task summarized in [13]. In the first method, the object creation and operations are coded, in which the query language, e.g. SQL, is embedded. This is more or less the same as ordinary database applications. The second method of implementing an IDL with a database aims at storing the IDL objects themselves in the database. To achieve this, some tasks must be carried out, like mappings between the object definition and a (relational) schema, coding to store and retrieve data from the database for an object, and loading the object from the database to the memory.
2.2.2. Federated IDL and/or application
Given a set of IDL specifications (each for a participating database), one can develop an application which may access the data from different databases through relevant CORBA servers and performs the processing.
We consider two kinds of applications. The first kind does not need a ‘global’ view of all databases of interest. These applications are aimed at directly accessing databases and performing the processing. Heterogeneities are resolved in the application program itself. Such an application can be created using a programming language like C++ or Java. There are no special requirements for this kind of applications compared to ordinary CORBA-based client applications except that the addresses of the CORBA servers for relevant databases are required.
The second kind of applications needs to access the participating databases through a unified interface, i.e. a ‘federated’ or ‘global’ IDL interface. In this case, the ‘IDL integration’ is required. A ‘federated IDL’ is similar to a federated schema in a federated database system.
In order to create an ‘integrated IDL’, we can review previous work on schema integration. Current methodologies can be divided into manual and semi-automatic ones [14]. Manual methodologies aim at providing a tool which allows the database administrator (DBA) to build, by himself, the integrated schema from local schemas. Semi-automatic methodologies use (1) a semi-automatic reasoning technique to discover correspondence assertions relating corresponding objects between two descriptions by evaluating some degree of similarity, e.g. names, structures and constraints; and (2) a semi-automatic integration technique to derive an integrated schema from a set of inter-schema correspondence assertions and integration rules. They are semi-automatic because the DBA will be invoked both to confirm or deny some plausible corresponding assertions and to solve some machine-unresolvable conflicts. Many consider completely automatic integration to be impossible since it would require that all of the semantics of the schema be completely specified [1].
Although there are some similarities between IDL integration and schema integration, we believe it is still an area worth exploring. Our approach is to start from the manual methodology and examine the requirements in the CORBA environment gradually, and evolve towards the goal of semi-automatic integration.
3. DATA DICTIONARY IN INTEGRATION
In a CORBA environment, the ‘interface integration’ can be achieved by the developer of the CORBA server for the federated IDL to identify the object relationships and resolve heterogeneities in the code. This method is practical and gives the developer a great deal of freedom to implement the integrated IDL to a very fine granularity. However, hardwiring the mapping in this way makes the system far more difficult to maintain. To avoid this problem, we need a facility to help construct the integration in a more dynamic way. For this purpose, we investigated the use of a data dictionary/directory (DD/D).
A DD/D plays an important role in schema integration in a multidatabase system. It is used to store information about the federated schema and mappings among schemas, schema-independent information (such as tables and functions for unit/format conversions), and various types of system information (such as addresses of each system hosting a component DBMS) [1]. This idea can be used in a CORBA environment, and we also propose this data dictionary be specified using the OMG IDL.
3.1. Data dictionary IDL design
The first part of the dictionary concerns database addresses. In our architecture, it is the CORBA server that deals with the access to an participating database. So a database address can be represented by a string which locates the CORBA server. The address may be in the form of a URL since at present most CORBA products support a naming service which accepts the URL string and binds to the CORBA server. The IDL fragment for this part is
string getAddress(in string db);
void putAddress(in string db, in string url);
void deleteAddress(in string db);
The second part is for object class mappings. Here we assume that an IDL file is designed in such a way that an object class corresponds to an IDL interface. A federated IDL interface (or class) may relate to a set of interfaces (or object classes) in the local IDL specifications. For example, a patient object class in a federated IDL may be relating to inpatient class in hospital_db’s IDL, and pregnant class in maternity_db’s IDL.
//description of a local object class
struct LocalObjClass {
string db;
string obj_class_name;
};
typedef sequence <LocalObjClass> LocalObjClassSeq;
LocalObjClassSeq getLocalObjClasses(
in string fed_obj_class);
void setLocalObjClasses(
in string fed_obj_class,
in LocalObjClassSeq local_obj_classes);
void deleteLocalObjClasses(
in string fed_obj_class);
The third part is concerned with mappings among the individual federal and local objects. For example, a patient Mrs. Smith in a federated class patient with a federal external identifier smith1960031209 is the same person in the class pregnant of the maternity system with case reference number (CRN) S1234567. Therefore, if each of the federal or local objects has an external identifier, the mappings among them may be stored in the dictionary and this will greatly facilitate the query processing.
struct LocalObject { //
string db; // local database name
string obj_class_name; //local object class
string obj_id; // local object's
// external identifier
};
typedef sequence <LocalObject> LocalObjSeq;
LocalObjectSeq getLocalObjects(
in string fed_oid);
void putLocalObjects(in string fed_oid,
in LocalOidSeq local_oids);
void deleteLocalObjects(in string fed_oid);
If object external identifiers are not available, the linkage between a federal object and local objects needs to be built up dynamically during the query processing. In this case, a ‘trader’ interface in the federated and local IDLs is usually needed. A trader interface is designed to provide a set of methods to produce a list of objects based on the attribute (property) values of the objects.
3.2. Data dictionary implementation
The data dictionary specified in the previous subsection can be implemented using a CORBA server. Basically, each part may be implemented with an underlying (hash) table. For instance, the table for the database addresses (part 1) will store a database name and its URL; the table for class mappings (part 2) store federated class name and corresponding local class specifications; and so for part 3. All the data in the dictionary of course needs to be persistent. A file, or a set of files, or a database can be used for this purpose. The implementation of methods in the dictionary interface is also quite straightforward, mainly involving retrieval from and insertion into the table.
As a summary of the issues discussed above, we present a system architecture of using CORBA for multidatabases, shown in Figure 2.
4. SYSTEM PROTOTYPE: A BIOLOGICAL APPLICATION
The Bioinformatics Group at the Roslin Institute is committed to providing animal genome mapping information services to the worldwide molecular biology community (http://www.ri.bbsrc.ac.uk/bioinformatics/). We have developed a generic genome database (ArkDB) to handle genome mapping data for single species [15], and currently we have a cluster of seven different species genome databases which use the same schema and interface. We have used Web technology for both information delivery and data editing [16]. We have examined applying CORBA technology for genome mapping in an Internet environment and built up an experimental CORBA-based genome mapping system [17, 18]. We designed an IDL specification for ArkDB, with the intent of reflecting the abstract schema of ArkDB and facilitating client application programming.
The requirement of ‘global biology’ has been well recognized by the biological research community [19]. Databases holding various biological data need to be interoperable to provide data sharing. One example in the genome research is comparative genome analysis. The analysis needs data from diverse genome databases, such as single species genome databases and DNA sequence databases. These databases are created and maintained by different institutions, and most likely are heterogeneous in terms of system, schema and semantics. Most genome data objects have an accession number, though the assignment of such a number may be effected in different ways.

We have developed a prototype system which takes an ArkDB and a model DNA sequence database as component databases. Each component database has an IDL specification and a federated IDL is constructed. The accession numbers of data objects in component databases are used as their external oids.
In our implementation, we have realized a ‘Trader’ interface is very useful in each local and the federated IDL, although each local and federal object has an external oid. For example, consider that a federal object is requested based on a set of property values. In our prototype, we assume that each IDL includes the following part:
struct Property {
string name;
any value;
}
typedef sequence <Property> PropertySeq;
typedef sequence <Object> ObjectSeq;
interface Trader {
ObjectSeq getObjects(in string obj_class,
in PropertySeq properties);
}
Method getObjects will search those objects of specified class qualified by properties. The properties is a sequence of name-value pairs, each of which specifies the property name and property value. We have taken advantage of IDL type any as property value, so making it possible to pass a very complicated data item. It should be noted that the concept of property introduced here is nothing to do with the Property Service in the CORBA specification.
The prototype was implemented using an evaluation copy of Visigenic’s Visibroker for Java (version 3.2). A relational database was used as a store for the data dictionary.
5. CONCLUSIONS
We have reviewed in this paper different forms of database interoperability: tightly coupled systems (through schema integration), loosely coupled systems (a multidatabase language is used for data access), as well as Web-based ‘loosest coupled’ approaches. As the CORBA is widely accepted for distributed application and as it is an open specification (i.e. not bound to any specific product), we believe it can be used as an infrastructure for database interoperability. We presented a system architecture derived from the classical 5-level FDBS architecture and discussed related topics in the CORBA environment, such as IDL integration, IDL design and an IDL’ized data dictionary.
We report an initial exploration of using CORBA for multidatabase interoperability. Many issues remain and need further investigation. For example, (a) the functionality of the data dictionary needs to be expanded so that it will include not only structural but also semantic information to help alleviate the heterogeneity problems [9]; (b) how to efficiently build up and maintain the data dictionary if the total data volume of the databases involved is large; (c) a programming environment which provides higher level tools to manipulate multi-IDLs (The proposal of building component tools for CORBA applications [20] may play an active role in this area).
References:
[1] A.P. Sheth and J.A. Larson, Federated databases systems for managing distributed, heterogeneous, and autonomous databases. ACM Computing Sruveys, 22, 1990, 183-236.
[2] D. Fang, J. Hammer and D. McLeod, The identification and resolution of semantic heterogeneity in multidatabase systems. Proceedings of the First International Workshop on Interoperability in Multidatabase System, IMS’91, 1991, Japan, 136-143.
[3] F. Saltor, M. Castellanos and M. Garcia-Solaco, Suitability of data models as canonical models for federated databases. SIGMOD Record, 20(4), 1991, 44-48.
[4] W. Litwin, A. Abdellatif, A. Zeroual, B. Nicolas and Ph Vigier, MSQL: a multidatabase language. Information Science, 49(1-3), 1989, 59-101.
[5] Netscape Communications Corporation, Netscape Object Signing: establishing trust for downloaded software. Technical White Paper, 1997 (URL: http://developer.netscape.com/library/documentation/signedobj/trust/owp.htm).
[6] OMG, Common Object Request Broker: Architecture and Specification (2.2). OMG Technical Documentation, 1998 (URL: http://www.omg.org/library/).
[7] S. Vinoski, Corba: Integrating diverse applications within distributed heterogeneous environments. IEEE Communications Magazine, 35(2), 1997, 46-55.
[8] R. Orfali, D. Harkey and J. Edwards, CORBA, Java, and the Object Web. Byte, October 1997, 95-100.
[9] M.P. Papazoglou, A. Delis and B.J. Kramer, Use of middleware facilities in interoperable databases, Computer Systems Science and Engineering, 10(4), 1995, 195-206.
[10] J. Slonim, J.W. Hong, P.J. Finnigan, D.L. Erickson, N. Coburn and M.A. Bauer, Does midware provide an adequate distributed application environment? IFIP Transactions C-Communication Systems, 20, 1994, 53-65.
[11] A. Beeharry, A. Bouguettaya and A. Delis, On distributed persistent objects for interoperable data stores. Informatics and Computer Science, 91, 1996, 1-32.
[12] J. Rumbaugh et al, Object-Oriented Modeling and Design. (Prentice Hall, 1991).
[13] B. Baker, CORBA and databases. Object Expert (Magazine), May 1996.
[14] S. Spaccapietra, C. Parent and Y. Dupont, Model independent assertions for integration of heterogeneous schemas, VLDB Journal, 1(1), 1992, 81-126.
[15] A.L. Archibald, J. Hu, C. Mungall, A.L. Hillyard, D.W. Burt, A.S. Law, and D. Nicholson, A generic single species genome database. XXVth International Conference on Animal Genetics (France), Animal Genetics, 27(Suppl 2), 1996, 55.
[16] C. Mungall, Visulisation tools for genome mapping - the Anubis map manager. XXVth International Conference on Animal Genetics (France), Animal Genetics, 27(Suppl 2), 1996, 56.
[17] J. Hu, C. Mungall, D. Nicholson and A.L. Archibald, Design and implementation of a CORBA-based genome mapping system prototype, Bioinformatics, 14(2), 1998, 112-120.
[18] C. Mungall and J. Hu, The Anubis map viewer: towards a component architecture (abstract), Objects in Bioinformatics, Oib-97, , Cambridge, UK, June 1997.
[19] R.J. Robbins, Bioinformatics: essential infrastructure for global biology, Journal of Computational Biology, 3(3), 1996, 465-478.
[20] IBM, Netscape, Oracle, and Sunsoft, CORBA Component Imperatives. Position Paper, 1997 (ORBS/97-05-25). (URL: http://www.omg.org/news/610pos.htm).