RAID-Systeme
RAID ist eine Technologie, die 1987 an der Universität von Californien, Berkeley, entwickelt wurde, um Plattenzugriffe zu beschleunigen und gleichzeitig durch Daten-Redundanz (Mehrfachspeicherung einer Information) die Ausfallwahrscheinlichkeit der Platten zu reduzieren.
RAID bedeutet:
Redundant Array of Independent Disks (mehrfach vorhandene Reihe von
unabhängigen Festplatten)
Ein Raid-System ist ein Zusammenschluss von mehreren Festplatten zu einem Datenverbund. Mehrere physikalische Platten werden nach außen hin wie eine Platte behandelt. Die Daten werden gezielt auf den verschiedenen Platten verteilt. So schützen diese fehlertoleranten Systeme die Daten, indem sie diese duplizieren oder auf unterschiedlichen physischen Medien speichern. Die Daten bleiben auch dann verfügbar, wenn das System teilweise ausfällt. Die Laufwerke können einzelne Fehler feststellen und die Originalinformationen im Falle eines Platten-fehlers wieder herstellen.
Arten:
Ursprünglich wurden die Raid-Level 0-5 definiert, wobei Mitte der 90er Jahre allerdings noch die Level 6 und 7 hinzugekommen sind.
Weiterhin gibt es zum Beispiel noch die Level 8 und 10. Das sind jedoch nur Raid-Kombinationen. Level 8 ist ein Zusammenschluss der Level 3 und 5. Raid 10 beispielsweise ist eine Kombination aus Level 0 und 1. Bei diesen Kombinationen handelt es sich also nicht um einen eigenen Raid-Level.
RAID 0
v Im RAID-0-System werden zwei oder mehr Festplatten zusammengeschaltet, um die Schreib-Lese-Geschwindigkeit zu erhöhen. So können zum Beispiel mehrere Schreib-Lesevorgänge parallel laufen.
v Die Platten werden in gleichgroße Stücke (Blöcke mit einer Größe von 4 bis 128 Kilobyte), sogenannte Chunks aufgeteilt. Hierauf werden die Daten gleichmäßig verteilt, so dass alle Platten gleichmäßig beansprucht werden.
v Es werden keine redundanten Informationen erzeugt. So gehen Daten verloren, wenn eine RAID-Platte ausfällt. Es lassen sich auch keine zusammenhängenden Datensätze reproduzieren. Die „0“ steht daher für „keine Sicherheit“ bzw. für „keine Redundanz“.

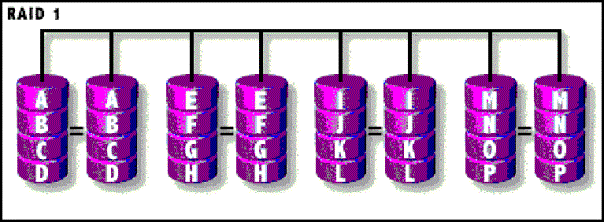
RAID 1
v In einem RAID-1-System werden auf zwei Festplatten identische Daten gespeichert. Da die „gespiegelte“ Platte ein exaktes Duplikat der Datenplatte ist, ergibt sich hieraus eine Redundanz von 100%. Fällt eine der beiden Platten aus, arbeitet das System mit der anderen Platte ungestört weiter. Dies erfolgt unbemerkt für das System, die Anwendung und den Benutzer. So ist zum Beispiel die hohe Datensicherheit von RAID 1 ein großer Vorteil.
v RAID 1 ist ein sehr teures System, da jede Festplatte zweimal vorhanden sein muss, einmal für die Daten und einmal für das „Spiegelbild“. So kann auch eine Erweiterung ebenfalls nur in Plattenpaaren erfolgen.
v Da bei RAID 1 die doppelte Plattenkapazität benötigt wird und sich das bei großen Datenmengen schnell bemerkbar macht, wird das System nur in relativ kleinen Servern eingesetzt.
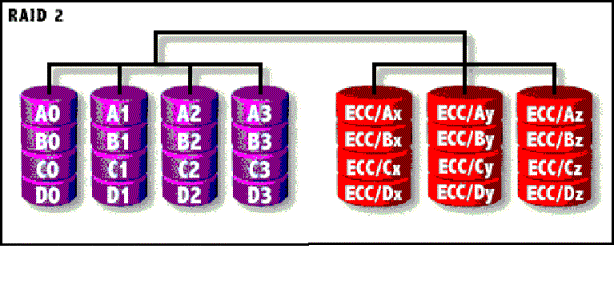
RAID 2
v Das RAID-2-System teilt die Daten in einzelne Bytes auf und verteilt sie systematisch auf den Platten. Für jeden Datensektor wird auf einer Prüfsummenplatte eine ECC-Information (Error Checking and Correction) gespeichert. Durch diesen Error-Correction-Code sind verschiedene RAM-Speichertypen in der Lage, interne Fehler zu erkennen und selbst zu korrigieren.
v Im RAID-2-System erfolgen die Schreib-Lesezugriffe gleichzeitig auf alle Platten.
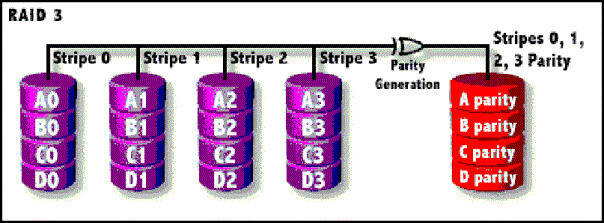
RAID 3
v In einer RAID-3-Konfiguration werden die Daten in einzelne Bytes aufgeteilt und dann abwechselnd auf meist 2 bis 4 Festplatten abgelegt. Für jede Datenreihe wird ein Parity-Byte hinzugefügt und auf einer zusätzlichen Platte, dem Parity-Laufwerk abgelegt.
v Unter Parity oder Parität versteht man in der EDV ein Prüfverfahren um etwaige Fehler bei der Datenübertragung zu entdecken.
v Fällt eine Platte aus, können die verlorengegangenen Informationen aus den verbliebenen Daten und den Parity-Daten rekonstruiert werden.
v Da moderne Festplatten jedoch nicht mehr mit einzelnen Bytes arbeiten, findet der RAID-3-Level kaum noch Verwendung.
RAID 4
v RAID 4 ist eine allgemein einsetzbare Lösung, insbesondere wenn viele Lesezugriffe im Vergleich zu den Schreibzugriffen nötig sind, zum Beispiel für Datenbankapplikationen.
v In RAID 4 werden die Daten blockweise mit Paritätsprüfung in Blöcken von 8, 16, 64 oder 128 Kilobyte aufgeteilt.
v Werden verteilte Schreibzugriffe vorgenommen, muss jedes Mal auf den Parity-Block zugegriffen werden. Daher ist RAID 4 für viele kleine Zugriffe nicht geeignet, das würde zu viel Zeit beanspruchen. Es eignet sich eher für den Zugriff auf große Datenmengen.

RAID 5
v In RAID 5 erfolgt die Datenverteilung blockorientiert mit gleichzeitiger Verteilung der Paritätsinformationen.
v Alle auf einer Ebene liegenden Platten bilden einen sogenannten Streifen.
v Über alle beschriebenen Stücke in einem Streifen wird eine Prüfsumme berechnet. Im ersten Streifen wird die Prüfsumme im letzten Stück gebildet, im nächsten Streifen steht sie im vorletzten Stück, usw. Auf diese Weise lassen sich die Daten komplett rekonstruieren, wenn eine Platte ausfallen sollte.
v So werden auch die Platten gleichmäßig beansprucht.
v Da in diesem System zusätzlich noch eine Festplatte benötigt wird, lohnt sich der Einsatz dieses Systems erst ab 4 Platten.
v Ein Nachteil bei RAID 5 ist der langsame Schreibzugriff auf die Platten. Um gute Datenverfügbarkeit zu gewähren, müssen nämlich bei jedem Schreibzugriff zunächst die alten Daten gelesen werden. Dann werden die neuen Daten eingegeben und die dazugehörigen Paritätsinformationen berechnet. Nun müssen die neuen Daten und die Paritätsinformationen auf wieder anderen Platten gespeichert werden.
v Daher sollte man das System durch einen Cache unterstützen, welcher die wichtigsten Daten zwischenspeichert. Das gewährleistet eine schnellere Schreibgeschwindigkeit.

RAID 6
v RAID 6 ist ein neues Verfahren, eine Weiterentwicklung der anderen RAID-Level.
v Es bietet die höchste Datensicherheit und wird somit nur bei äußerst sensiblen Daten angewendet.
v In diesem Level können bis zu zwei Festplatten ausfallen ohne dass ein Datenverlust entsteht.
v Hier werden pro Streifen (Platten auf einer Ebene) zwei voneinander unabhängige Checksummen berechnet. Das Speicherverfahren basiert auf der Speichertechnik von RAID 5. Es wird jedoch noch eine weitere unabhängige Paritätsinformation auf ein zusätzliches Laufwerk gespeichert, was die Schreibzugriffe wieder etwas verlangsamt.
RAID 7
v Auch RAID 7 ist ähnlich wie RAID 5 aufgebaut. Es ist ebenfalls eine Weiterentwicklung der anderen RAID-Level.
v Der Unterschied zu RAID 5 liegt nur darin, dass in der RAID-7-Steuereinheit ein zusätzliches lokales Echtzeitbetriebssystem eingesetzt wird. RAID 7 nutzt ebenfalls schnelle Datenbusse und mehrere größere Pufferspeicher. So werden nochmals die Vorgänge gegenüber anderen Verfahren erheblich beschleunigt.
v Ähnlich wie bei RAID 6 können die Daten anhand der Paritätsinformation für ein oder mehrere Laufwerke generiert werden.