La memoria es un recurso escaso, y para aprovecharla bien hay que administrarla bien. A pesar de que la memoria es más barata cada día, los requerimientos de almacenamiento crecen en proporción similar. Por otra parte, la memoria más rápida es obviamente más cara, por lo que la mayoría de los computadores tiene una jerarquía de memoria. Por ejemplo, en un Pentium típico:
La forma más simple de administrar memoria es ejecutando sólo un programa a la vez, compartiendo la memoria con el sistema operativo. Por ejemplo, MS-DOS, en direcciones crecientes de memoria: Sistema operativo; programa de usuario; manejadores de dispositivos (en ROM). Cuando usuario digita un comando, el sistema operativo carga el programa correspondiente en la memoria, y lo ejecuta. Cuando el programa termina, el sistema operativo solicita un nuevo comando y carga el nuevo programa en la memoria, sobreescribiendo el anterior.
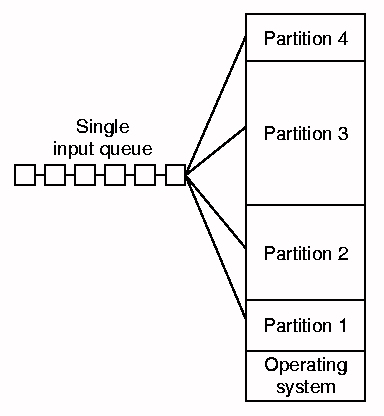
Ya hemos hablado bastante de las ventajas de la multiprogramación, para aumentar la utilización de la CPU. La forma más simple de obtener multiprogramación es dividiendo la memoria en n particiones fijas, de tamańos no necesariamente iguales, como lo hacía el IBM 360 en la década del 60.
Puede haber una cola de trabajos por partición, o bien una sola cola general. En el primer caso, cuando llega un trabajo, se pone en la cola de la partición más pequeńa en la que todavía quepa el trabajo. Si llegan muchos trabajos pequeńos podría pasar que, mientras las colas para las particiones chicas están llenas, las particiones grandes quedan sin uso. En el caso de una sola cola, cada vez que un programa termina y se libera una partición, se escoge un trabajo de la cola general. żCómo escoger?
Bajo multiprogramación, si un mismo programa se ejecuta varias veces, no siempre va a quedar en la misma partición. Por ejemplo, si el programa, ejecutando en la partición 1 (que comienza en la dirección 100K) ejecuta un salto a la posición 100K+100, entonces, si el mismo programa ejecuta en la partición 3 (que comienza en 400K), debe ejecutar un salto a la posición 400K+100, porque si salta a la 100K+100 va a caer en la memoria que corresponde a otro proceso. Este es el problema de la reubicación, y hay varias formas de resolverlo.
Consideremos un programa en assembler, donde las direcciones se especifican
de manera simbólica, como es el caso de la variable count y la
entrada al ciclo loop en el siguiente fragmento de programa:
LOAD R1, count
loop: ADD R1, -1
CMP R1, 0
JNE loop
La ligadura o binding de las direcciones count
y loop a direcciones físicas puede realizarse en:
100: LOAD $210, R1 102: ADD R1, -1 104: CMP R1, 0 106: JNE 102
En este caso el código debe cargarse a partir de la dirección 100.
Pero además de la reubicación tenemos el problema de la protección: queremos que un programa ejecutando en una partición no pueda leer ni escribir la memoria que corresponde a otra partición. Podemos entonces matar dos pájaros de un tiro con una variante de los registro base y límite que vimos en el capítulo 1. Cuando se carga un programa en una partición, se hace apuntar base al comienzo de la partición, y límite se fija como la longitud de la partición. Cada vez que la CPU quiere accesar la dirección d, el hardware se encarga de que en realidad se accese la dirección física base+d (y, por supuesto, además se chequea que d<límite).
Decimos que d es la dirección lógica o virtual, y base+d la dirección física. El programa de usuario sólo ve direcciones lógicas; es la unidad de administración de memoria (MMU) quien se encarga de traducirlas transparentemente a direcciones físicas. La gracia es que el compilador puede generar código absoluto, pensando que el programa se va a cargar siempre en la posición 0, y en realidad el binding se hace en tiempo de ejecución.
Si en un sistema interactivo no es posible mantener a todos los procesos en memoria, se puede usar el disco como apoyo para extender la capacidad de la memoria: pasar procesos temporalmente a disco.
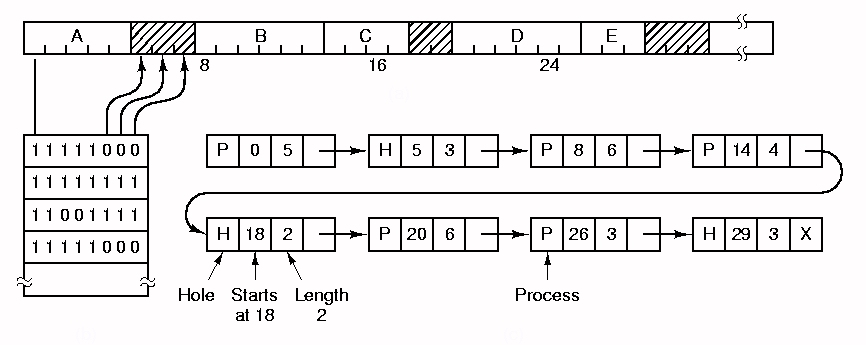
El sistema operativo mantiene una tabla que indica qué partes de la memoria están desocupadas, y cuáles en uso. Las partes desocupadas son hoyos en la memoria; inicialmente, toda la memoria es un solo gran hoyo. Cuando se crea un proceso o se trae uno del disco, se busca un hoyo capaz de contenerlo, y se pone el proceso allí.
Las particiones ya no son fijas, sino que van cambiando dinámicamente, tanto en cantidad como en ubicación y tamańo. Además, cuando un proceso es pasado a disco, no hay ninguna garantía de que vuelva a quedar en la misma posición de memoria al traerlo de vuelta, de manera que es imprescindible el apoyo del hardware para hacer ligadura en tiempo de ejecución.
Si los procesos pueden crecer, conviene reservar un poco más de memoria que la que estrictamente necesita al momento de ponerlo en memoria. Al hacer swapping, no es necesario guardar todo el espacio que tiene reservado, sino sólo el que está usando. żQué pasa si proceso quiere crecer más allá del espacio que se le había reservado?
Otro punto que hay que tener en cuenta al usar swappping, es el I/O que pudiera estar pendiente. Cuando se hace, por ejemplo, input, se especifica una dirección de memoria donde se va a poner lo que se lea desde el dispositivo. Supongamos que proceso A trata de leer del disco hacia la dirección d, pero el dispositivo está ocupado: su solicitud, por lo tanto, es encolada. Entretanto, el proceso A es intercambiado a disco, y la operación se completa cuando A no está en memoria. En esas circunstancias, lo leído se escribe en la dirección d, que ahora corresponde a otro proceso. żCómo se puede evitar tal desastre?
Podemos dividir la memoria en pequeńas unidades, y registrar en un mapa de bits las unidades ocupadas y desocupadas. Las unidades pueden ser de unas pocas palabras cada una, hasta de un par de KB. A mayor tamańo de las unidades, menor espacio ocupa el mapa de bits, pero puede haber mayor fragmentación interna. Desventaja: para encontrar hoyo de n unidades hay que recorrer el mapa hasta encontrar n ceros seguidos (puede ser caro).
Otra forma es con una lista ligada de segmentos: estado (ocupado o en uso), dirección (de inicio), tamańo. Cuando un proceso termina o se pasa a disco, si quedan dos hoyos juntos, se funden en un solo segmento. Si la lista se mantiene ordenada por dirección, podemos usar uno de los siguientes algoritmos para escoger un hoyo donde poner un nuevo proceso.
Cada vez que se asigna un hoyo a un proceso, a menos que quepa exactamente, se convierte en un segmento asignado y un hoyo más pequeńo. Best-fit deja hoyos pequeńos y worst-fit deja hoyos grandes (żqué es mejor?). Simulaciones han mostrado que first-fit y best-fit son mejores en términos de utilización de la memoria. First-fit es más rápido (no hay que revisar toda la lista). Se puede pensar en otras variantes.
Los métodos anteriores de administración de memoria sufren el problema de la fragmentación externa: puede que haya suficiente espacio libre como para agregar un proceso a la memoria, pero no es contiguo. La fragmentación puede ser un problema severo. En algunos sistemas usar first-fit puede ser mejor en términos de fragmentación; en otros puede ser mejor best-fit, pero el problema existe igual. Por ejemplo para first-fit, las estadísticas hablan de un tercio de la memoria inutilizable por estar fragmentada. Una forma de resolver este problema es usando compactación de la memoria: mover los procesos de manera que queden contiguos. Generalmente no se hace por su alto costo. Si se usa, no es trivial decidir la mejor forma de hacerlo.
Por otra parte, supongamos que tenemos un segmento desocupado de 1000 bytes, y queremos poner un proceso de 998 bytes de tamańo, lo que dejaría un hoyo de 2 bytes. Difícilmente otro proceso podrá aprovechar esos dos bytes: es más caro mantener un segmento en la lista que "regalarle" esos dos bytes al proceso. La fragmentación interna se produce cuando un proceso tiene asignada más memoria de la que necesita.
Esto de que los procesos tengan que usar un espacio contiguo de la memoria es un impedimento serio para optimizar el uso de la memoria. Idea: que las direcciones lógicas sean contiguas, pero que no necesariamente correspondan a direcciones físicas contiguas. O sea, dividir la memoria física en bloques de tamańo fijo, llamados marcos (frames), y dividir la memoria lógica (la que los procesos ven) en bloques del mismo tamańo llamados páginas.
Se usa una tabla de páginas para saber en que marco se encuentra cada página. Obviamente, se requiere apoyo del hardware. Cada vez que la CPU intenta accesar una dirección, la dirección se divide en número de página p y desplazamiento u offset d. El número de página se transforma en el marco correspondiente, antes de accesar físicamente la memoria.
El tamańo de las páginas es una potencia de 2, típicamente entre 0.5 y 8K. Si las direcciones son de m bits y el tamańo de página es 2n, entonces los primeros m-n bits de cada dirección forman p, y los restantes n forman d. Este esquema es parecido a tener varios pares de registros base y límite, uno para cada marco (o sea, ligadura en tiempo de ejecución).
Cada proceso tiene su propia tabla: : cuando la CPU se concede a otro proceso, hay que cambiar la tabla de páginas a la del nuevo proceso. La paginación en general encarece los cambios de contexto. La seguridad sale gratis, ya que cada proceso sólo puede accesar las páginas que están en su tabla de páginas.
żFragmentación? Sólo interna, y de media página por proceso, en promedio. Esto sugeriría que conviene usar páginas chicas, pero eso aumentaría el sobrecosto de administrar las páginas. En general, el tamańo de página ha ido aumentando con el tamańo de la memoria física de una máquina típica.
Si las direcciones son de m bits y el tamańo de página es 2n, la tabla de páginas puede llegar a contener 2m-n entradas. En el PDP-11 m=16 y n=13; una relación poco usual, pero basta con 8 entradas para la tabla de páginas, lo que permite tener 8 registros de CPU dedicados especialmente a tal propósito. En una CPU moderna, m=32 (y ahora, incluso, 64), y n=12 o 13, lo que significa que se requerirían cientos de miles de entradas: ya no es posible tener la tabla en registros.
Lo que se puede hacer es manejar la tabla de páginas de cada proceso completamente en memoria, y usar sólo un registro que apunte a la ubicación de la tabla. Para cambiar de un proceso a otro, sólo cambiamos ese registro. Ventaja: agregamos sólo un registro al cambio de contexto. Desventaja: costo de cada acceso a memoria se duplica, porque primero hay que accesar la tabla (indexada por el número de página). O sea, si sin paginación cada acceso costaba 70ns, ˇahora cuesta 140!
Solución típica (intermedia): usar un pequeńo y rápido caché especial de memoria asociativa, llamado translation look-aside buffer (TLB). La memoria asociativa guarda pares (clave, valor), y cuando se le presenta la clave, busca simultáneamente en todos sus registros, y retorna, en pocos nanosegundos, el valor correspondiente. Obviamente, la memoria asociativa es cara; por eso, los TLBs rara vez contienen más de 64 registros. El TLB forma parte de la MMU, y contiene los pares (página, marco) de las páginas más recientemente accesadas. Cuando la CPU genera una dirección lógica a la página p, la MMU busca una entrada (p,f) en el TLB. Si está, se usa marco f, sin acudir a la memoria. Sólo si no hay una entrada para p la MMU debe accesar la tabla de páginas en memoria (e incorporar una entrada para p en el TLB, posiblemente eliminando otra).
Por pequeńo que sea el TLB, la probabilidad de que la página esté en el TLB (tasa de aciertos) es alta, porque los programas suelen hacer muchas referencias a unas pocas páginas. . Si la tasa de aciertos es del 90% y un acceso al TLB cuesta 10ns, entonces, en promedio, cada acceso a memoria costará 87ns (żpor qué?). O sea, sólo un 24% más que un acceso sin paginación. Una Intel 80486 tiene 32 entradas en el TLB; Intel asegura una tasa de aciertos del 98%.
En cada cambio de contexto, hay que limpiar el TLB, lo que puede ser barato, pero hay que considerar un costo indirecto: si los cambios de contexto son muy frecuentes, la tasa de aciertos se puede reducir (żpor qué?).
Otra ventaja de paginación: permite que procesos compartan páginas. Por ejemplo, varios procesos ejecutando el mismo código: las primeras páginas lógicas apuntan a las mismas páginas físicas, que contienen el código. El resto, apunta a datos locales, propios de cada ejecución.
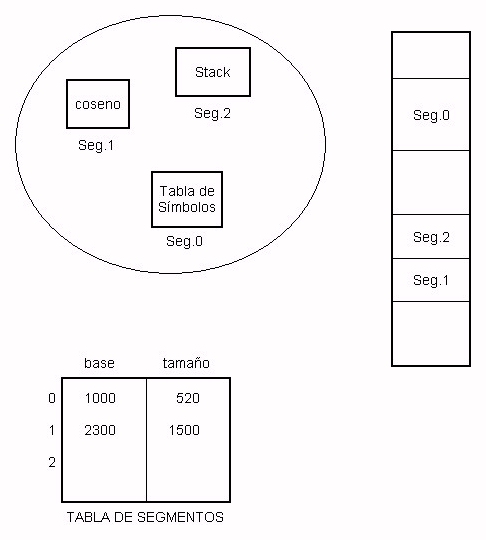
Cuando se usa paginación, el sistema divide la memoria para poder administrarla, no para facilitarle la vida al programador. La vista lógica que el programador tiene de la memoria no tiene nada que ver con la vista física que el sistema tiene de ella. El sistema ve un sólo gran arreglo dividido en páginas, pero el programador piensa en términos de un conjunto de subrutinas y estructuras de datos, a las cuales se refiere por su nombre: la función coseno, el stack, la tabla de símbolos, sin importar la ubicación en memoria, y si acaso una está antes o después que la otra.
La segmentación es una forma de administrar la memoria que permite que el usuario vea la memoria como una colección de segmentos, cada uno de los cuales tiene un nombre y un tamańo (que, además, puede variar dinámicamente). Las direcciones lógicas se especifican como un par (segmento, desplazamiento).
Similar a paginación: en vez de tabla de páginas, tabla de segmentos; para cada segmento, hay que saber su tamańo y dónde comienza (base). Una dirección lógica (s,d), se traduce a base(s)+d. Si d es mayor que el tamańo del segmento, entonces ERROR.
Ventajas:
Pero la memoria sigue siendo, físicamente, un sólo arreglo de bytes, que debe contener los segmentos de todos los procesos. A medida que se van creando y eliminando procesos, se va a ir produciendo, inevitablemente fragmentación externa.
Si consideramos cada proceso como un sólo gran segmento, tenemos el mismo caso que el de las particiones variables. Como cada proceso tiene varios segmentos, puede que el problema de la partición externa se reduzca, pues ya no necesitamos espacio contiguo para todo el proceso, sino que sólo para cada segmento. Para eliminar completamente el problema de la fragmentación interna, se puede usar una combinación de segmentación y paginación, en la que los segmentos se paginan.
En una 80386 puede haber hasta 8K segmentos privados y 8K segmentos globales, compartidos con todos los otros procesos. Existe una tabla de descripción local (LDT) y una tabla de descripción global (GDT) con la información de cada grupo de segmentos. Cada entrada en esas tablas tiene 8 bytes con información detallada del segmento, incluyendo su tamańo y dirección. Una dirección lógica es un par (selector, desplazamiento), donde el desplazamiento es de 32 bits y el selector de 16, dividido en: 13 para el segmento, 1 para global/local, y 2 para manejar la protección. La CPU tiene un caché interno para 6 segmentos.