 |
|
|
|
|
|
|
|
|
To think about the issue of data collection means you are wondering about the characteristics of the methods used. Each method have it's own advantages and inconveniences. With each technic you might also found a few people who will disapprove its use for such or such reason.
What you should keep in mind when choosing a technic or another, is to understand its characteristics. Then, you will be in a more comfortable position to cope with its disadvantages and you will be able to retrieve all information you can access with this method.
The webmaster : Frédéric D'Astous
|
|
Note : As soon as an article is translated, its title and description will be translated accordingly.
The advisers and specialists as documentary sources - The contribution of advisers and specialists can be very important for a research. Those persons can be helpful at two specific moments. First, when you search for documentary sources, they give you the human element. Second, sometimes they will be those you will interview to gather your data.
Choosing words for questions related to a frequency of use - When your doing a survey, it is better to avoid the vague terms in your questionnaire. Everyone, had the occasion to read surveys with questions like: "do you often use service XYZ?" But, what is the meaning of : often ?
The focus group - What we can call a "focus group" is an interesting technique. It allows an interaction among the persons. This quality is also its inconvenience!
How to link the goal of a survey with the questionnaire. - How to build a questionnaire on such or such subject ? The answer to this question will always depend on the circumstances of each survey. You can solve this problem by following a method.
The issues related to practical assessment of a margin of error. - If there is an obsession widely spread among those who do surveys, it is the margin of error. Everybody wants to know at which degree the results of the survey are reliable. To resolve this problem, most will trust statistical probability. But ...
Is it an efficient strategy to use a questionnaire created by someone else ? - The idea seems beautiful. Wouldn't it be some saving of time by using a questionnaire that is already made. Especially if it's one that was already used in a real life situation ?
Overview of survey methodology - Here is a serie of articles dedicated to the realization of surveys. This series was published on this site during the second part of 1999. The proposed method takes into account various practical situations which can occur when you need to do a survey. Also, those articles includes links to some others of this website.
The various topics covered are :
The role of hypothesis when you're planning a survey - Some recommend to identify hypothesis at the beginning of a search. Such identification can enable the researcher to clarify the nature of what should be measured. But, it is not always possible nor desirable.
The structure of a questionnaire - The conception of a questionnaire is an important step. To be sure to have all chances of success, you must know exactly what you're seeking for.
Various factors influencing a margin of error - When someone have to gather data, it is likely he will try to build a quantitative study. The logic of this choice is: it will be more precise. Indeed, it will be possible to have an evaluation of the statistical precision of the results. Everything will seem so perfect ! Unfortunately, things are not so simple.
Les corrélations et les causalités - On s'imagine souvent qu'il y a un lien entre deux phénomènes lorsqu'ils varient d'une manière similaire. Or, ce n'est pas toujours le cas !
La courbe normale utilisée en statistiques - Pour décrire la plupart des phénomènes humains, on utilise la forme en cloche de la courbe normale. Cette forme correspond à des comportements observables.
|
|
|
![]()
|
|
At the beginning of a research (by survey or otherwise), it can be important to look for documentary sources. It is what some will call : " the review of papers ". And here, I use the term documentary sources in the widest meaning of this term. Indeed, the goal is not to find only written sources. These documentary sources can be:
In practice, the advisers can be useful at two specific moments of a research.
The purpose of the gathering of documentary sources is to allow you to have a better idea of what have been said or written about your subject. It is not for the intellectual beauty of the matter which you should do that. The search for documentary sources should allow you to put a more adequate glance at the data you will later gather.
What leads us towards this topic ? It is questions like this one I found in my e-mails: " If I finally gather my data through advisers or specialists, do I need to also gather documentary sources? "
Usually, the answer will be "yes". Without an efficient gathering of documentary sources a problem (related to the individuals you might have to interview) might pop-up later in the process of data gathering. Indeed, those persons usually have a precise point of view. They know very well a portion of the problem. That is why you gather your data through them. They provide the human element so useful for the understanding of things.
Unfortunately, it is this same human element which is likely to cause a phenomenon similar to the lack of objectivity. Obviously, this phenomenon will play a role both in the process of gathering documentary sources and the process of gathering data. For now, let's start with the gathering of documentary sources.
I say here "a similar phenomenon", because it would be a little careless to say that a person, specialized in a domain, automatically lacks objectivity. A person who specialized in a specific field, on the contrary, often have the necessary knowledge to avoid any inappropriate saying. It is not a blatant lack of objectivity which it is in question here, but rather of an adverse effect of the specialization.
The perspective of a person who works in a precise domain, or on a particular ground, will be "always influenced" or "directed" by the peculiarities of its domain or its ground. So, this person will have developed a very specific expertise in a particular sector of knowledge. By trusting exclusively this specialist, it is likely that some aspects of your research might become invisible. This danger is more insidious since you will have very keen information in various aspects of your research. You will feel secured ...
To resolve this problem of "specialization", you should make sure to consult other advisers. It can be useful to try to meet persons having an expertise slightly different from the first. So, you will be more able to easily noticed in what the specialization of every advisers is centred on specific topics rather than others.
But, there is another problem. It is that I would call it : the effect of influence. As I called it sooner, the fact of consulting a person rather than a book (or any other written source) adds a human element to the information. It is this human element which risks to later modify your own perspective.
When one is in presence of a set of new information, something can happen. The process of understanding is influenced by two factors: the information and the links you will do with this information. The first is tangible and quantifiable while the second is intangible and then unquantifiable. It is with the second aspect that the human element will interact. You are likely to adapt your understanding according to what the adviser told you. And because this influence is difficult to pinpoint, it will be difficult to avoid every risk. Those risks are more prominent if your rely only upon specialists and advisers.
To avoid this last stumbling block, it will be interesting to make a gathering of documentary sources that includes written sources. These sources will help you to have a more neutral glance on your research. So, you will be less dependent on your advisers for your own understanding. Furthermore, the information which you will find there, shall enable you to interact more actively with any adviser or specialist.
Good research!
Your webmaster : Frédéric D'Astous.
![]()
|
|
Many visitors of my website ask me : "how to build a questionnaire on such or such subject? " There are many answers to that question. It will always depend on the circumstances characterizing each survey. All surveys are threatened by many difficulties when it is time to decide how to ask questions. All those threats share a common characteristic. How to communicate to the person what we precisely want to know. Fortunately, it is relatively easy to solve this problem by following a method.
Initially, it is important that the researcher specifies its global objective. Which problem does he want to solve? What is "the" reason for this survey? It is what will makes it possible to avoid asking futile questions. Too much often, a questionnaire is lengthened by questions which seem interesting, but are irrelevant regarding the goal of the survey.
It is important, to never forget that a long questionnaire is also implying biggest difficulties to have it adequately filled. It is a paramount issue to clearly state the priority of a survey. Beware, you must resist to the temptation of identify more than one objective. In some cases, the difficulty to identify only one goal could camouflage a lack of precision with the elements you wish to measure by doing your survey.
Secondly, you must decide how your objective will be divided. That will gives you what is called dimensions. Each dimension constitutes a type of elements that shall measure in order to fulfill the requirements of our global objective. For example, if our global objective is :"having a portrait of the summer jobs found by students ", our dimensions could be: the student, his field of study and the summer job.
In third place, there is the identification of what will enable us to "measure" our dimensions. It is what we can call : indicators. Each indicator represents one of the measures to be taken to have a precise idea of the composition of our dimension. That means, each indicator shall represents the goal of a question. But, what you measure by each question is called : variable. Thus, the relation between the variable and the indicator is the following : the indicator is the objective of the question whereas the variable is its answer, its "measurement". In our example, one of our dimensions was "the field of study". One of our indicators and its variable could be: identification of the program measured either by the name of the program of study or or by the field of study. Note that if a dimension can regroup several indicators, there should be only one variable for each indicator. So, the variable is "the" measurement of the indicator.
The following diagram will enable you to visualize the components of our example:
By proceeding in this manner, you gain various advantages. You know exactly how many questions to ask, the contents of those questions and furthermore, you decrease the chances to end up with an ambiguous question somewhere.
In fourth place, all that it left to do, it is to write down your questions and carry out a pretest. What is important there, is to identify people that share similar characteristics with those you want to reach in your survey. In doing so, you will be able to pinpoint any misleading element in your questionnaire. You are now ready to use your questionnaire in the real life. I wish you a good survey!
Your webmaster : Frédéric D'Astous
![]()
|
|
If there is an obsession uniformly spread among those who realize surveys, it is the margin of error. Everybody wants to know at what degree the results of his survey are reliable. To resolve this problem, most will trust statistical probability. Indeed, the science of the statistics gives us numerous formulae to quantify the probability of this or that. Generally, the results of these computations can be reliable if the survey is done with care, and if one is not in the presence of too many uncontrolled factors.
There is major stake: uncontrolled factors. The object of this article is to see how these factors can impaired the precision of a survey. This is made in the idea manage " to control these unverifiable "! What is an uncontrolled factor? It is the small detail which seems coarse. But this small detail, such the peel of proverbial banana, is likely to cause significant difficulties in the following steps of a survey.
First of all, let us address the issue of the base of calculation. For some, the simple fact of knowing the quantity of contacted people (the sample) and then, making a comparison with the quantity of those who might have been potentially reached (the population) is sufficient to make a calculation. And it is true, that from this information, you can use a formula or consult a table. But, all these beautiful calculations are useless if your sample was not chosen in a probabilistic fashion.
Why? Simply because the statistical error is not the only one. Methods, not probabilities, are likely to cause important distortions. In a sample that is not probabilistic , there might be some types of respondents which might stay hidden. some other types might be oversampled. These distortions will echo on the results of the survey.
Besides, the simple fact of realizing a probabilistic sampling is not sufficient. A probabilistic sample is often made from a list. Now, a list of names is far from being neutral. For example, a source as usual as the phone book can cause problems. People who move frequently are not accurately included. Confidential numbers do not appear to it. It is what causes distortions.
As a consequence, there is not only the statistical error to be considered. One often underestimates the distortions which result either from the constitution of the sample, or from the other factors. The problem of these distortions? They are not calculable! It is little as if they did not exist. As if they were invisible. But, they are very real.
Another cause of error lies in the structure of questionnaires. This last one can have for consequence to direct the respondent. Let us imagine a pressure group which uses a questionnaire approaching "capital punishment". Near the end of this questionnaire, one asks a question like " Do you agree or Disagree with capital punishment ?" Now, this question is preceded by several others aiming to identify the fear level of the respondent related to crime. Because of the sequence of questions, it is likely that the proportion of persons who agree with the capital punishment will increase. The overall logic of the questionnaire might look like this : "If you believe that the rate of crime is a big problem, you should be in favor of the "capital punishment". This can control this by paying attention to the sequence of questions in the questionnaire. It will be sometimes useful to insert some questions with neutral character into the sequence. It contributes to break the effect of influence of one question on the others.
There is also the wording of the questions which can play a role. Let's take the same problem, if you have a question like "Do you agree with the capital punishment" Agree or Disagree. Even though you clarify the alternative, Agree or Disagree, in your choice of answers, your question is faulty. You ask to your respondent if he "Agrees". You implicitly suggest to him to answer "Agree". You are still distorting your results.
How to estimate margin of error in a situation where the risks of errors can result of everywhere? You can try to compare your results with some reliable data. Let us imagine that you have access to precise data that were gathered with a known methodology. You should be able to find in your results, the same proportions as in the study which you use as reference. It is as if you realized a test to know if you are able of measure an already known proportion.
This comparison method a little looks like a game of riddles. And you will never be totally certain that your error will be uniform, throughout the survey. Certain results can be more reliable than the others. A comparison can be useful if you well know the reliability of the source of data being of use to the comparison. Furthermore, these data must be applicable to your case. For example, the assessment of the unemployment rate is often the result of a very particular methodology. You cannot compare this rate with the quantity of persons who say, in your questionnaire, who they have no job. Besides, the unemployment rate varies many from the time to the other one. The variations are sometimes very fast. You should then make sure to have data which are still valid at the time of your study.
As you can see, to only trust the statistical error is insufficient to give a precise image of the reliability of a survey. There are numerous other types of errors. Now, only some were talked about here. And, their most insidious characteristic is, they do not appear at the researcher under a form which allows an easy mathematical assessment. That is why, the only track of solution reside in the methodological caution and then, when it is possible, in the comparison with already existing data.
Your webmaster : Frédéric D'Astous.
![]()
|
|
When your doing a survey, it is better to avoid the vague terms in your questionnaire. Everyone, had the occasion to read surveys with questions like: "do you often use service XYZ?" But, what is the meaning of : often ? For some, this "often", will mean: 2 times per week. For others it will be: 2 times per month! However the two individuals who answered, will honestly claim to use "often" the service. As a consequence, all answers will not be usable.
The solution is then to use words that refers directly to the "frequency of use" of the service. Then, our question can be : "do you use this service more than 2 times per week? " But, there is still another point to consider for evaluating our question: "is the service used on a regular basis or on an occasional basis? "
If the customers use the service on an occasional basis, that means the intensity of the use will not be constant. Then, it is useful to include a reference to a period of time that can be use by those who will answer to our survey. Is this during the last month? The last year? Then, our question can become : "During the last month, did you use service XYZ at least 2 times? "
Furthermore, it is possible that this discontinuity of use is related to some particular condition. If it is the case, it will be necessary to use preliminary questions to "measure" any detail that can be useful to understand the circumstances related to the use of the service. The kind of the service will help to decide what will be preliminary questions to ask. Now, it will be time to write our questions. Then, it might look like this :
The reader can see significant differences between each question. It is logical, since the wording of each question is related to the context resulting from the preliminary questions. But, in all cases, the goal is the same. It is the identification of a frequency of visit by referring to some particular circumstances, which were introduced by preceding questions. Thus, the researcher should not need to modify the objectives of each questions according to the sequence of questions in the questionnaire. The goal of each question should be set before writing the questions. It is what enable us to carry out these 2 steps by different persons, if necessary. Then, a consultant can be employed to create the framework of the questionnaire, whereas someone else can be in charge of the creation of the questionnaire itself according to that actual circumstances prevailing at the moment of the survey.
The webmaster: Frédéric D'Astous.
|
to use a questionnaire created by someone else ? |
Several visitors of this website wants to use an already made questionnaire on the subject which interest them. Thus, I regularly have questions on how to find examples on such or such topic. The idea seems beautiful. Wouldn't it be some saving of time by using a questionnaire that is already made. Especially if it's one that was already used in a real life situation ?
In practice, everything is not so simple. A questionnaire is the combination of two groups of factors. On one hand, each questionnaire is based on the specific needs that presides to its creation. On the other hand, each questionnaire is influenced by various characteristics related to the environment for which it was built. Thus, you must keep in mind that you cannot have two situations structured exactly in the same way.
Obviously, there are situations where a level of similarity can be observed. Paradoxically, it is such similarity that might be a perilous trap. Why ? When confronted to a questionnaire that is radically different from its needs, the researcher will be able to quickly locate the various incompatibilities. The adaptation of the questionnaire will be reasonably feasible. But, when confronted to a questionnaire that have a higher degree of similarity, the things can no more be so simple. An effect related to the common sense is likely to occur.
The common sense is the tendency to accept what is usual, as self evident. The common sense usually helps us in the everyday life. Because of it, we know how to behave in situations which are known to us. It is also because of it that we still be able to behave in new situations. It is because we establish links with what we know : our life experience.
Then, any factor that can seems in contradiction with that common sens, is consequently relegated to the background. So, if you are confronted to a questionnaire implying a significantly high degree of similarity, you are likely to accept its overall logic. That means you might overlook your own needs. Then, if incompatible elements are present, they might easily become invisible. So in order to avoid this effect, you will probably need a questionnaire so different that it might be useless ...
The only way of getting rid of the effect caused by the common sens, is to describe precisely what is the structure of the problem at the origin of your survey. Thus, you become able to clarify each detail of your needs. Your goal will be to identify each element which can play a role in the subject of your survey.
The procedure of clarification was described in another article entitled : How to link the goal of a survey with the questionnaire. The importance to identify each factor lies in the fact that these are forming the basis which will enable you to identify relevant questions. For more details on how to describe a problem, the reader will have to refer to this article. All the details of the procedure are given there.
In conclusion, it is not a very good idea to re-use an already made questionnaire as a base for your own survey. The common sens is likely to distort your vision of things. This, to the point where the logic of the questionnaire will seems obvious to you. It is from there, that you are likely to ignore the characteristics of your own situation and consequently creat an unefficient questionnaire. Each case is different ! You'd better take this into account or you might loose some precious time to learn it !
The webmaster: Frédéric D'Astous.
|
|
Some recommend to identify hypothesis at the beginning of a search. The point in support of this procedure is that such identification will enable the researcher to clarify the nature of the elements to be measured. However, at the beginning of search, it is sometimes difficult to know what could be the links between the elements of what we wish to study. Consequently, trying to anticipate the characteristics of such or such relation seems futile. Then, some simply avoid such identification of hypothesis. They consider that the data gathered will undoubtedly reveal some links which should be interesting to explore.
That point of view is logical. Very often the procedure of data gathering can lead you to important elements. The data themselves will reveal other clues. Then, the role of the hypothesis seems even more futile. But, for that conclusion to be correct, it is necessary to care about a few factors.
In the first place, it will be necessary that the procedure of identification of the components of the research was made thoroughly. For example, the hierarchical relations between the dimensions and the indicators must be precise. That precision will ensure that the researcher is aware of the characteristics of what he studies. For more details on this topic, the reader can consult the article entitled: How to link the goal of a survey with the questionnaire.
In the second place, the wording of the questions as well as the types of answers awaited of the respondent must be designed to ensure a "flexibility" in the analysis of the results. Indeed, in a scenario where the researcher would not have formulated hypothesis, the data gathered will have to be in a format which should not limits the subsequent analysis. Indeed, it is only when the researcher starts to examine the results that he will be able to see the relations on which it is logical to focus his energies. This is why one must avoid finding oneself with results which would stop, upon the departure, of the possibilities of analysis. To avoid this trap, the researcher will have to know exactly what he must measure to be able to make decision on the formulation of the questions.
If those conditions are met, it is probable that the researcher will be able to work without hypothesis. This procedure is particularly useful for an exploratory search where one does not have enough information to formally identify such hypothesis. I consider personally that the hypothesis are not essential to a search. It would however be necessary to avoid underestimate the advantages that can result from the formal identification of hypothesis. Among those advantages, we can point out the following :
In the first place, the use of hypothesis will make it possible to verify the relevance of the identification of dimensions and indicators. Here, I mean that the elements identified those that are useful to perform the analysis. Hypothesis are playing here the same role as questions. All it is to do, is to examine the table of dimensions and indicators while asking ourselves whether or not, we have the necessary elements to reach an answer our questions (our hypothesis).
In the second place, the identification of hypothesis will makes it possible to make sure there is an adequacy of the methodology used, regarding the goals of the research. Sometimes, a survey is not the best methodological choice. By knowing the kind of analysis that you will have to make, it will be easier to determine the method to be used. For example, if you want information related to what was lived by people regarding a social issue (e.g.: sexual aggressions) it might be more efficient to proceed with interviews. Thus, you will have access to a broader range of individual experiences. This will give you a better understanding of what is happening. On the contrary, if you need more factual information, a survey could be more profitable. It takes less time and gives you access to a greater quantity of cases, all this at a smaller cost.
In the third place, the identification of hypothesis will makes it possible to guide the construction of your questionnaire. The hypothesis can help you pinpoint unwanted interactions between the questions. The priority of each of your questions will be clearer. Then, it will be easier to determine the proper sequence of the questions. Also, the hypothesis can help you to know what kind of information will be necessary to perform your analysis. Then, the wording of the questions can be eased. It will also be easier to choose the types of question to ask (with a choice of answers, without one, ...).
As you can see, the use of hypothesis is not essential. The utility of hypothesis lies in the fact that they allow a better identification of our needs. This can also be achieved by a thorough verification of the hierarchical relations between the dimensions and the indicators. But, if you have some trouble to figure the structure of what you want to analyses, making hypothesis will surely help you in your work.
Your webmaster : Frédéric D'Astous.
|
|
The conception of a questionnaire is an important step. To be sure to have all chances of success, you must know exactly what you're seeking for. Thus, you'll know exactly what will be the goal of each question. What to do in this preliminary stage was discussed in the article : How to link the goal of a survey with the questionnaire. The issue here is to identify precisely what must be measured. Talking about precision implies 2 things :
The content of the questionnaire :
1 - Presentation : It is important to inform the respondent about the motive of the study. Who makes the study and how the information will be used. The goal is to inform him just enough to have the participation of the respondent, while avoiding directing the respondent on the content of the desired answers.
2 - Information on procedure : They allow the respondent to know how to answer your questionnaire. It's better to indicate those information at the exact place where it is necessary. Usually some general infromation are useful at the beginning while the others more specific will be placed in more specific places (For exemple : just before a question).
3 - The sequence of questions : Make sure all parts of the questionnaire appears in a logical sequence to the respondent. He has to undestand that he is engaged in a structured procedure. To do that, you can, among other strategies, regroup questions by subject or by type (choice of answers, opened questions, dichotomic questions, ...)
It is essential to place sensitive questions at the end of a questionnaire. Sensitive questions can cause a refusal to answer. And if a respondent refuses to answer the first questions of a questionnaire, he usually decides not to answer to the questionnaire itself.
It is also essential to place questions related to the characteristics of the respondent at the end of a questionnaire. People usually consider that a survey has to guarantee the confidentiality of all answers. The information which describe the respondent easily causes refusals to answer. It can be seen as a proof that you do not care for confidentiality. If the person decides not to answer the last questions, you have just lost some information, but the questionnaire is still useful.
4 - Questions used as filters : It might happend that portions of a questionnaire are useful only for some respondents. It is customary then to ask a question that can help to sort the respondents. Then, each choice of answers will lead the repondent where to find the question relevant to its particular situation.
For example :
Why are you a part-time worker ?
By choice......................
(__)
---> Go to question 9
Because of the employer .......
(__)
---> Go to question 18
Other..........................
(__)
---> Go to question 21
Afterward, a reminder is also customary before every question where the respondant is told to go. Here, a reminder should be indicated before questions 9 , 18 and 21. This reminder allows to reassure the respondent. He knows he is at the right place. Every time a respondent encounter a difficulty while answering to a questionnaire, there is a risk he will put aside the questionnaire.
5 - Final thank you. It is important that the respondent know his effort was appreciated. If sensitive information was collected you have to, again, reassure the respondent about the use of this information. It is then useful to make reference to the precaution you will take to protect the confidentiality of the answers.
Have a good survey !
Your webmaster: Frédéric D'Astous![]()
|
|
This method of research is used to obtain information on the reactions of a group of persons about a fact, about a situation.
The advantage of this method, is the variety of the information it help to discover. A discussion among the participants can allows you to access information that can be equivalent, and even exceeds, to that of the conventional survey. Why ? Each time an idea is submitted to the group, the participants react. So, it is possible to dynamically investigate an idea. Each time, you can find a whole spectrum of reactions. However, this method is sometimes inadequate.
Let us examine two points which allow you to gauge the inconveniences of "focus group":
Any situations with some level of controversy is likely to produce effects which tend to impair the validity of results. People often tend to answer so as to conform to the expectations they perceive from the group or from the interlocutor. If a comment is at risk to be considered as wrong, it is likely that the participant will avoid to say it.
Often, people tend to please. Let us imagine a discussion group which is related to the company " XYZ inc. " The participants are shown various products of this company. There is a risk that only few negative comments will be heard. The participants might avoid criticizing the products, or they might minimize the inconveniences related it.
To make a success of a group of discussion, it is not to realize a beautiful debate. It is to harvest useful information. A lively discussion can be interesting. But, this easily adds elements that might be hardly measurable. Wanted information risks to be immersed in the debate as if it were masked. To make a successful use of the discussion group strategy, it is sometimes useful that the composition of the group is relatively homogeneous. Make sure to avoids effects caused by any opposition among the participants.
Good discussion!
Your webmaster : Frédéric D'Astous
![]()
|
|
Dans un sondage, on tente d'obtenir habituellement 2 genres de résultats. La premier type de résultats recherché c'est l'obtention de données sur chacune des questions. Le second type de résultats recherché c'est l'identification des liens entre les données précédentes pour voir s'il y a des relations entre certains résultats. C'est alors qu'on parle de corrélation.
La corrélation est le fait, pour deux variables, d'évoluer d'une manière qui soit liée. Cette liaison peut se faire dans le même sens ou encore dans un sens qui est l'inverse. Ce qui compte, c'est qu'il y ait un lien pour entre les variables. Par exemple, dans les deux graphiques suivants, il y a corrélation.
 |
|
 |
On tente souvent de faire des liens entre différents phénomènes. En fait, identifier des relations est souvent un des objectifs que se fixe celui qui désire faire un sondage. On tentera de voir si deux variables évoluent d'une manière reliée. Si c'est le cas, il sera tentant de conclure à la présence d'une relation de cause à effet entre les deux. Il faut cependant faire preuve de prudence.
En effet, des variables peuvent se comporter de la même manière sans qu'il n'y ait pour autant une relation de cause à effet. Si on observe un lien entre deux variables, il y a 3 options possibles :
- 1 - soit la relation est purement accidentelle,
- 2 - soit le relation en est une de cause à effet,
- 3 - soit la relation dépend de l'influence d'une troisième variable.
Tout d'abord, le premier cas, il se peut que la relation soit accidentelle. Cela voudra dire que malgré les apparences, il n'y a pas de liens entre les deux. Si on veut en avoir le coeur net, il sera prudent de vérifier la possibilité inverse : est-il est possible d'identifier un mécanisme par lequel une variable pourrait en influencer une autre. Une fois ce mécanisme identifié, il faudra vérifier si on possède des éléments pour en prouver la présence, et puis, prouver que c'est bien ce mécanisme qui est en action. On le voit, la preuve n'est pas toujours facile à faire.
Le second cas se produira s'il est possible d'identifier un mécanisme d'influence. Cela démontrera que la relation n'est probablement pas purement accidentelle. En présence d'un tel mécanisme, on sera tenté de crier victoire ! Mais attention, il se peut que ce mécanisme implique une troisième variable. On devra donc s'assurer que le mécanisme s'articule de sorte qu'il y ait, bel et bien, un lien direct entre les deux variables et non pas un lien indirect.
Le troisième cas se présente lorsqu'une troisième variable sert d'intermédiaire entre les deux. Une troisième variable peut être présente, mais si elle n'est pas entre nos deux variables, il s'agit du second cas (deux variables qui interagissent directement ensemble) et non pas de ce troisième cas. Ce dernier détail (la position de la variable dans la relation) est bien important. Prenons l'exemple suivant :
Un chercheur tente une étude comparative de la température et du moral des gens, dans des régions comme la Gaspésie, nord du Nouveau-Brunswick ou certains secteurs de Terre-Neuve. Ce chercheur note une relation qui ressemble à ceci : plus la température est élevée et moins il y a de gens déprimés. Il en déduit que lorsque la température est plus élevée, les gens sont plus actifs (donc moins déprimés). Il est heureux de sa découverte. En fait, il ne devrait pas car il lui manque un détail. L'activité économique de ces régions est caractérisée par diverses occupations saisonnières dont la maximum est atteint en été, lorsqu'il fait chaud. Il n'y a donc aucun lien direct entre l'état psychologique des gens et la température. Par contre, il se peut qu'on puisse faire un lien du genre : lorsqu'il fait froid, le choix d'activités économiques est moins varié. Il y a donc plus de chômage et certaines personnes en sont démoralisées en raison des problèmes monétaires que cette situation entraîne. Aucun lien direct entre la température et le moral des gens!
La prudence est donc de mise lorsqu'on tente de prouver la présence d'une relation entre diverses variables et les mécanismes qui les unissent. Il importe d'examiner l'ensemble des possibilités pour voir si les liens qu'on tente d'établir sont les bons.
Votre conseiller : Frédéric D'Astous
![]()
|
|
Pour décrire la plupart des phénomènes humains, on utilise la forme en cloche de la courbe normale. Cette forme n'est pas seulement le résultat d'une création statistique quelconque. Elle correspond à des comportements observables que les statisticiens ont représentés sous la forme d'une cloche.
Ainsi, l'observation nous apprend que les variations que présentent ces phénomènes se manifestent fréquemment de manière progressive. C'est ce qui explique les pentes de chacun des côtés de la cloche. De plus, on peut remarquer que le comportement de groupes s'organise souvent autour de certaines règles. Ce genre de comportement explique la présence d'une tendance centrale.
Globalement, on obtient donc cette forme de cloche comme nous le montre la figure 1. Afin de permettre une meilleure comparaison, la silhouette de la courbe normale a été ajoutée par dessus notre diagramme en bâtons. La manière avec laquelle les données seront réparties autour de la tendance centrale nous permettra du jauger l'importance de cette valeur. En effet, on tendra à considérer que les relations entre nos résultats sont fortes si ils sont bien regroupés autour de la valeur centrale.
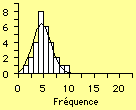 |
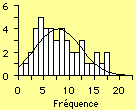 |
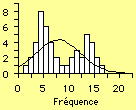 |
|
|
|
|
À l'inverse, si nos valeurs sont distribuées très largement autour d'une valeur maximum, on tendra à considérer qu'il n'y aura pas de lien déterminant entre nos divers résultats. La figure 2 nous donne un exemple de ce genre de relation peu significative. Pour s'en convaincre, le lecteur n'a qu'à examiner la courbe qui présente des côtés très évasés. De plus, on remarquera la présence de plusieurs endroits où les valeurs semblent remonter. C'est un peu comme si, à l'intérieur de nos résultats, se cachaient plusieurs tendances. En règle générale, plusieurs tendances c'est un peu comme s'il n'y en avait aucune.
Mais, il arrive parfois que plus d'une tendance soit un indice intéressant. C'est ce qui arrive lorsqu'on est capable de distinguer nettement les tendances présentes. La figure 3 nous donne un exemple de cette situation. On voit très bien la présence des deux pics. L'interprétation à donner lorsqu'on observe cette forme, c'est de conclure à la présence de deux groupes distincts.
Une analyse de l'ensemble des variables devrait normalement permettre d'isoler chacune des deux clientèles. L'analyste devra tenter d'identifier la ou les facteurs déterminants pouvant permettre de caractériser les groupes de répondants. Certains logiciels permettent de trier les données de manière à faire ressortir certaines caractéristiques. Dans le cas de la figure 3, il est probable que l'on trouvera dans les données qui accompagnent ce résultat, une variable qui, lorsqu'on la prend en compte, permettra de faire disparaître l'un ou l'autre groupe selon la valeur (ou le plage de valeurs) qu'elle prendra.
Signé : Frédéric D'Astous.
![]()
|
|
Les personnes qui font un sondage n'ont pas toujours sous la main des listes de noms permettant de réaliser une sélection aléatoire des répondants. Les sondeurs sont alors obligés d'utiliser des techniques qui font appel à des compromis. C'est là qu'entre en ligne de compte le jugement du sondeur pour éviter que les compromis ne mettent en péril la validité du travail.
L'échantillonnage accidentel fait justement partie de ces techniques à employer avec circonspection. En gros, la technique accidentelle consiste à se placer à un endroit donné et à questionner chaque première personne d'un nombre "x" de personnes rencontrées. Par exemple, un commercent peut mettre en pratique cette méthode en questionnant le premier client de chaque série de 10 clients.
Ce qui semble rassurant dans cette procédure, c'est qu'on a tendance à considérer que les personnes (ou les clients de notre exemple) se présentent sans un ordre particulier. On a donc l'impression que le hasard est à l'oeuvre et qu'en conséquence : la procédure est totalement neutre et objective. Or, rien n'est plus faux. Le rythme de vie de nos sociétés est soumis à des cycles et des horaires. Dans la pratique cela signifie que, à certains moments, on rencontrera un type de clientèle qui sera inexistant à une autre moment.
On se pensera alors que le commerçant de notre exemple n'aura qu'à réaliser ses entrevues pendant toute une journée. Ainsi, les variations horaires seraient éliminées et on obtiendrait un portrait adéquat de l'ensemble de la clientèle de l'établissement. Mais encore là, la prudence est de mise. Certains types de clientèle vont varier en fonction du jour de la semaine alors que d'autres suivent de lentes variations saisonnières.
Dans la pratique que devra faire le sondeur ? Tout d'abord, il sera essentiel de vérifier à quel groupe de personnes le sondage s'adressera puis de vérifier comment ce groupe se divise. Cela peut se faire en contactant les personnes qui interagissent avec les gens qu'on veut joindre. Ces informations ne nous donneront pas un portrait précis de la situation mais à tout le moins nous saurons quelles sont les principales caractéristiques à surveiller. Dans notre exemple, les vendeurs du commerce ont probablement remarqué la présence de certains types de clientèle à des moments particuliers. Cette information nous permettra de définir les moments où il faudra réaliser la démarche de sondage. Si les vendeurs n'ont pas noté de différence entre la clientèle de chacune des soirées de semaines, on réalisera une économie en ne sélectionnant qu'une seule soirée. Et on fera ainsi pour chacune des périodes qui semblent se distinguer.
Si on décide de s'arrèter là, on obtiendra un portrait de chacun des moments importants où il est possible de rencontrer un type ou un autre de la clientèle ciblée. Mais, il est possible que le commercant de notre exemple cherche à obtenir des résultats pour l'ensemble de sa clientèle. Il lui faudra alors pondérer ses résultats pour tenir compte du pourcentage de clients qui correspond à chaque moment particulier de fréquentation de son établissement. Ainsi, si la clientèle du soir représente 30% de la fréquentation du commerce, on considérera que les résultats de nos entrevues d'une soirée représentent l'état de 30% de la clientèle. Et on procèdera de cette manière pour l'ensemble de nos résulats (clientèle de fin de semaine, d'après-midi, de matinée, ...) Il est possible d'utiliser des logiciels statistiques (par exemple, du genre tableur) pour arriver à pondérer nos résultats.
Il reste une seule chose à régler et c'est la source des données servant à notre pondération. Dans notre exemple, il sera important d'utiliser le nombre de clients qui fréquentent le magasin. En effet, si notre commercant utilise son chiffre d'affaire, il introduira une distortion provenant de la taille des ventes individuelles , laquelle n'est probablement pas constante pour tous les types de clientèle. S'il utilise le nombre de ventes ce sera la même chose car certains types de clientèle sont plus difficiles que d'autres. En utilisant ce dernier indicateur, certaines portions de la clientèle seraient probablement sous-estimées au bénéfices de certaines autres.
Bon sondage.
Le responsable de ce site : Frédéric D'Astous.
|
|
|
.![]() .
.